아침뉴스 파이프라인의 소스 선정과 스크래핑 전략
뉴스 자동화 시스템을 운영하다 보면 가장 먼저 맞닥뜨리는 현실적인 문제가 어떤 소스를 선택하느냐와 그 소스에서 어떻게 안정적으로 데이터를 수집하느냐입니다. 2026년 4월 14일, 저희 시스템은 실제로 뉴스 미수집과 텔레그램 발송 동시 장애를 겪었고, 그 경험을 바탕으로 이 글을 씁니다.
1. 소스 선정 원칙
1-1. RSS 피드를 1순위로 활용하라
뉴스 수집에서 가장 안정적인 방법은 공식 RSS/Atom 피드를 사용하는 것입니다. 스크래핑과 달리 사이트 구조 변경에 영향을 받지 않으며, 대부분의 언론사에서 공식 지원합니다.
- 국내 추천: 연합뉴스, YTN, KBS, MBC, SBS 공식 RSS
- 기술 뉴스: GeekNews(geeknews.kr), Hacker News, The Verge
- 카테고리별 RSS를 별도로 구독하면 정확도 향상
1-2. 소스 다각화로 단일 장애점 제거
단 하나의 소스만 구독하면 해당 소스 서버 장애 시 전체 파이프라인이 멈춥니다. 최소 3개 이상의 독립 소스를 병렬로 구독하고, 각 소스에 fallback 우선순위를 지정하는 것이 권장됩니다.
2. 스크래핑 전략 및 도구 선택
2-1. 도구 선택 기준
| 도구 | 특징 | 추천 상황 |
|---|---|---|
| feedparser (Python) | RSS/Atom 전용, 경량, 안정성 최고 | 뉴스 RSS 수집 1순위 |
| requests + BeautifulSoup | HTML 파싱, 유연성 높음 | RSS 없는 사이트 보조 수집 |
| Playwright/Puppeteer | JS 렌더링, 헤드리스 브라우저 | SPA/동적 페이지 최후 수단 |
2-2. 중복 수집 방지
같은 기사를 여러 번 수집하면 요약/발송 시 중복 알림이 발생합니다. 해결 방법:
- 각 기사의
guid또는 URL을 SQLite/파일에 기록 - 수집 전 중복 체크 후 신규 기사만 처리
- 수집 주기와 기사 TTL(보존 기간)을 일치시켜 오래된 항목 자동 정리
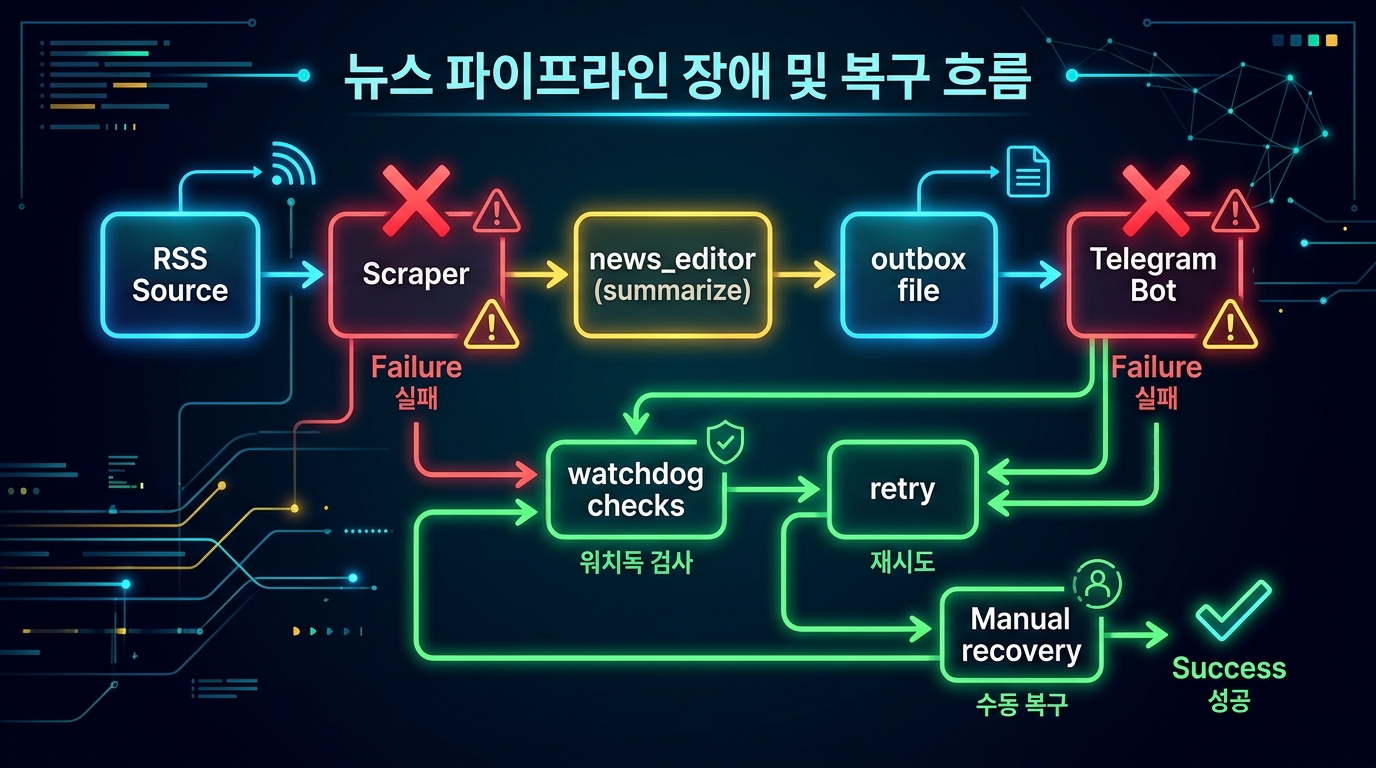
3. 2026-04-14 실전 장애 사례 및 복구 루틴
발생 상황
- 뉴스 미수집: 오전 9시 수집 크론이 실행되었으나 소스 서버의 일시적 응답 지연으로 수집 파일이 생성되지 않음
- 텔레그램 발송 실패: 수집 파일 없음으로 인한 빈 파이프라인 → 텔레그램 전송 스크립트가 빈 메시지를 전송하려다 오류로 종료
복구 단계별 조치
- 1단계 자동 감지: watchdog 크론이 outbox 파일 미생성을 감지 (10분 이내)
- 2단계 news_editor 재실행: main agent가 news_editor 서브에이전트에 수동 수집 명령 재발행
- 3단계 파일 검증: outbox/telegram_message_clean.txt 존재 여부 확인 후 유효 데이터 검증
- 4단계 직접 발송: 재수집 완료 후 main agent가 직접 텔레그램 전송 실행
- 5단계 로그 기록: 장애 발생 시각·복구 소요 시간·원인을 memory 파일에 기록
개선 대책
- 소스 서버 타임아웃 값을 10초 → 30초로 상향
- 수집 실패 시 즉시 알림 발송(텔레그램 장애 알림 별도 채널 또는 메모)하여 조기 인지
- fallback 소스 자동 전환 로직 추가
4. 운영 노하우 요약
- RSS 피드는 15~30분 주기 폴링이 적당 (너무 짧으면 서버 차단 위험)
- 수집 스크립트는 반드시 예외처리(try/except) + 타임아웃 설정
- 크론잡 실행 결과를 항상 로그 파일에 기록하고 watchdog으로 모니터링
- 주요 소스별 수집 성공률을 주기적으로 점검해 불안정 소스는 교체